AWS備忘録
俺用メモ
業務や勉強で出てきたキーワードやメモを雑にまとめている記事。(随時更新するかも)
VPC
AWS上に好きな構成のネットワークを構築出来る。
使い方
1. VPCのトップへ
2. メニューからVPCを選択する
3. VPCの作成
サブネット
VPCで作成したプライベートなネットワーク空間を、さらにCIDRブロックで分割することが出来る。
10.0.0.6 というCIDRブロックをVPCとして割当たところをさらに /24 の大きさで分割するなど。
10.0.0.0/16(10.0.0.0 ~ 10.0.255.255)
↓ /24 分割
10.0.0.0/24(10.0.0.0 ~ 10.0.0.255)
10.0.1.0/24(10.0.1.0 ~ 10.0.1.255)
色々ある
10.0.254.0/24(10.0.254.0 ~ 10.0.254.255)
10.0.255.0/24(10.0.254.0 ~ 10.0.255.255)
使い方
- メニューからサブネット選択
- サブネット作成
- どこで?とからへん設定する
インターネットゲートウェイ
VPCで作成した領域、サブネットをインターネットに接続する。イメージ的には、自分のネットワークにインターネット回線を引き込む作業。
インターネットゲートウェイを作成して、作成したものにチェックして、VPCにアタッチする。
しかし、このままでは、インターネットに接続が出来ません。具体的にやるべき作業としては、「0.0.0.0/0 の範囲の宛先パケットは、インターネットゲートウェイに転送する」という設定をルートテーブルに設定する。(ルートテーブルについては、別項目で詳しく)ちなみに、0.0.0.0/0 は全てのIPアドレスを指している。つまり、「転送先が何も設定されていないものは、デフォルトの転送先にするという意味になります」これをデフォルトゲートウェイという。
使い方
ルートテーブルにサブネットの追加
- ルートテーブル作成
- 作成したものを選択
- サブネット関連付けを編集
- 割り当てしたいサブネット選択する。
ルートを編集(デフォルトゲートウェイ)
- ルートテーブルを選択
- ルートを編集
- 別のルートを追加
- 0.0.0.0/0とigwから始まるターゲットを設定する
ルートテーブル
TCP/IPのネットワーク機器である「ルータ」が、「宛先IPアドレス」を見て、「もっとも宛先IPあどれすに近い方のネットワーク」へと、パケットを転送して、最終目的地にパケットを到達させてます。この仕組には、ルータが、「どちらのネットワークが、より宛先IPあどれすに近いか」を事前に知っておかないと、うまく機能しません。
実際には、VPCを作った時点で、デフォルトのルートテーブルや、サブネット作成時にデフォルトのルートテーブルが適用されるので、意識しなくてもいい。
確認方法
サブネットから、特定のVPCを選ぶ、ルートテーブルが下に出てきているので、それを押すと、特定のルートテーブル情報が出てくる。下のタブで実際に設定されているルートテーブルが出てくる。
ルートテーブルは以下のような設定を持ちます。
宛先アドレス(ディスティネーション) 流すべきネットワークの入り口となるルーター(ターゲット)
簡単な例
ルータ1が知っているサブネットはCIDR0とCIDR1
ルータ2が知っているサブネットはCIDR2とCIDR3
CIDR0がCIDR3に通信するためには、ルータ1とルータ2を経由する必要がある。
設定する値
ルータ1
| ディスティネーション | ターゲット |
|---|---|
| CIDR0 | local |
| CIDR1 | local |
| CIDR2 | ルータ2 |
| CIDR3 | ルータ2 |
ルータ2
| ディスティネーション | ターゲット |
|---|---|
| CIDR0 | ルータ1 |
| CIDR1 | ルータ1 |
| CIDR2 | local |
| CIDR3 | local |
ドメイン名と名前解決
www.example.co.jp -> 54.250.90.112 と解決するやつ
使い方
適当な名前を自動でつける場合
独自ドメイン名をつける場合
レジストラと呼ばれるドメイン事業者から、利用したいドメイン名を取得する。AWSのコンソールから取得する他にも、JIRSの指定業者から取得も可能。
DNSサーバーを構築するためにRoute 53というサービスが提供されています。これに取得したドメイン名を設定すると独自ドメイン名を利用出来るようになります。ちなみに、このRoute 53を使ってドメイン名を取得することも可能です。
NATゲートウェイ
内側からインターネットは利用したいけど、外部からの接続を避けたい時は、IPマスカレードの機能を利用することで実現出来る。利用ケースとしては、閉じたサブネットからのライブラリとかのインストールは許可したいよねー。けど、外からのアクセスはいらないよねーみたいな。
- メニューからNATゲートウェイを選択する
- NATゲートウェイの作成
- 対象サブネットと適当なElastic IPを割り当てる
- ルートテーブルに
0.0.0.0/0natIDを設定。 - 閉じたネットワークにいるインスタンスからcurl投げてみる
EC2
EC2を使うことで、仮想サーバーを作成することが出来る。この仮想サーバーのことは「インスタンス」と呼びます。このインスタンスには、サブネット内で利用可能な「プライベートIPアドレス」を割り当てます。しかし、インターネットからの接続にプライベートIPアドレスは使えません。そこで出てくるのが「パブリックIPアドレス」です。AWSで割り当てられているIPアドレスぶろっくのうちの適当なものが使われます。
使い方
インスタンスの停止と再開について
停止すると課金対象から外れ、コストを下げることが出来る。しかし、インタウンスが使っているストレージのEBSは容量を確保している間は課金対象となります。もし、完全に課金を止めたい場合は削除すれば良いのですが、一度削除したインスタンスは二度と復活しないので気をつけること。
パブリックIPアドレスを固定化する
ElaticIPというのを使えば出来る。
SSHで接続する
今回はパブリックIPアドレスを使ってアクセスする。(Mac環境で)
$HOME/.ssh/config に以下のノリで設定する
Host ec2 User ec2-user Port 22 Hostname 13.131.219.17 IdentityFile ~/.ssh/my-key.pem
以下のようなエラーが出たら、chmod 400 keyとかでいける。内容としては他のユーザーでも読めるよねー。うん。みたいなノリ。
$ ssh ec2
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: UNPROTECTED PRIVATE KEY FILE! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Permissions 0644 for '/Users/jumpei/.ssh/my-key.pem' are too open.
It is required that your private key files are NOT accessible by others.
This private key will be ignored.
Load key "/Users/jumpei/.ssh/my-key.pem": bad permissions
Permission denied (publickey).
$ chmod 400 /Users/jumpei/.ssh/my-key.pem
$ ssh ec2
Last login: Sun Jun 10 12:19:54 2018 from 103.2.241.5
__| __|_ )
_| ( / Amazon Linux AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/
10 package(s) needed for security, out of 12 available
Run "sudo yum update" to apply all updates.
[ec2-user@ip-10-0-1-10 ~]$
ファイアウォールで通信を制限する(セキュリティグループ)
パケットフィルタリング
流れるパケットを見て、通過の可否を決める仕組みです。
パケットにはIPアドレスの他、ポート番号やそれに付随するものを見て、通過の可否を決めます。
- インバウンド 外側から内側へ
- アウトバウンド 内側から外側へ
使い方
設定内容確認
- メニューからセキュリティグループ
- 該当のセキュリティグループを選択
- インバウンド選択
- ルールが見れる
Webサーバの例
- インスタンスのIPアドレスを取得(パブリックIPとか)
- 外部からそのIPアドレスでアクセスしてみる(デフォルトだと22番以外許可されていないから)
- インスタンスのセキュリティグループを確認して編集
- 今回だと、インバウンドに0.0.0.0/0 に 80番ポートの許可
- 2でアクセスしたIPへ再度アクセス
SNS(Simple Notification Service )
SNSはpub/sub メッセージング/モバイル通知サービス。
例えば、YARUO というワードをSNSから送るとこんな感じになる。
これを使って、Lambdaをキックしたり出来る。
{ "Records": [ { "EventSource": "aws:sns", "EventVersion": "1.0", "EventSubscriptionArn": "arn:aws:sns:ap-northeast-1:85166933371:HelloWorld:2d9efed1-e6ee-4778-9045-d0ad7e0e4481", "Sns": { "Type": "Notification", "MessageId": "4094aa4b-81fe-5b4c-bbb2-f9233432590", "TopicArn": "arn:aws:sns:ap-northeast-1:51669633371:HelloWorld", "Subject": "None", "Message": "YARUO", "Timestamp": "2018-06-12T11:37:33.401Z", "SignatureVersion": "1", "Signature": "T...b6EHMpgAP3D3usg+DKshVqwL1t74Q==", "SigningCertUrl": "https://sns.ap-northeast-1.amazonaws.com/SimpleNotificationService-eaea6120e66ea12e88dcd8bcbddca72.pem", "UnsubscribeUrl": "https://sns.ap-northeast-1.amazonaws.com/?Action=Unsubscribe&SubscriptionArn=arn:aws:sns:ap-northeast-1:85169633371:HelloWorld:2defed1-e6ee-4778-9045-d0ad7e0e4481", "MessageAttributes": {} } } ] }
SMS メッセージには、最大で 160 個の ASCII (または 70 個の Unicode) 文字を含めることができます。 メッセージがこの長さを超える場合、Amazon SNS はそれを複数のメッセージとして送信し、それぞれが文字数の制限以内に収められます。 メッセージは単語の途中ではなく、全単語の境界で切り離されます。
使い方
CloudWatch
lambdaなどの標準出力をログ取ってくれたり、色々ログ取ってくれるやつ。
アラーム設定で、AutoScallingやSNS通知の発行などが出来る。
AlermのSNSの例
ただ、なんのエラーが起きたかは分からないので、巻き取る方法を作る必要がある。
{ "Records": [ { "EventSource": "aws:sns", "EventVersion": "1.0", "EventSubscriptionArn": "arn:aws:sns:ap-northeast-1:851669633371:HelloWorld:2d9efed1-e6ee-9045-d0ad7e0e4481", "Sns": { "Type": "Notification", "MessageId": "ba186730-a68f-534b-ada6-34a9609753de", "TopicArn": "arn:aws:sns:ap-northeast-1:851669633371:HelloWorld", "Subject": "ALARM: \"lambda-error\" in Asia Pacific (Tokyo)", "Message": "{\"AlarmName\":\"lambda-error\",\"AlarmDescription\":\"lambda-error-desc\",\"AWSAccountId\":\"851669633371\",\"NewStateValue\":\"ALARM\",\"NewStateReason\":\"Threshold Crossed: 1 out of the last 1 datapoints [1.0 (12/06/18 12:58:00)] was greater than or equal to the threshold (1.0) (minimum 1 datapoint for OK -> ALARM transition).\",\"StateChangeTime\":\"2018-06-12T13:00:07.954\"}", "Timestamp": "2018-06-12T13:00:08.005Z", "SignatureVersion": "1", "Signature": "LB8YEGkR8QazvxNPBxiwzXF4OUtjJIIiJKiDx5c6PGrvRO1/cHMdSncdEcxy0w==", "SigningCertUrl": "https://sns.ap-northeast-1.amazonaws.com/SimpleNotificationService-e.pem", "UnsubscribeUrl": "https://sns.ap-northeast-1.amazonaws.com/?Action=Unsubscribe&SubscriptionArn=arn:aws:sns:ap-northeast-1:851669633371:HelloWorld:2d9efed1-4778-9045-d0ad7e0e4481", "MessageAttributes": {} } } ] }
firehoseと組み合わせると便利っぽい。
サブスクリプションを使用したログデータのリアルタイム処理 - Amazon CloudWatch ログ
SQS(Simple Queue Service)
シンプルなキューサービス。出来るのは、データ投入・取り出し・削除のみ。 命令を作る側と、命令を受け取る側でいい感じに分けれる。
よく使うコマンド
プロセス確認
ps -ax
ポートの状況見る
sudo lsof -i -n -P
名前解決確認
nslookup hoge.com
分からないを認識して、分からないと言う話
なんとなく知っているは知らない
社会人になって色々出来ないことはあるだろうけど、絶対これだけはやろうって考えていたのが、「分からないを認識して、分からないと言う」でした。 というのも、学生時代やりがちだったのが、「なんとなく知ってる」話を、「あーなるほど完全に理解したわ(知ってるだけ)」みたいなノリで、話を進めていた。それのせいで、痛い目にあったというよりは、ある会社のインターンのメンターさんに、「分からないを分かった風にしているのがだめ」と言われた一言で、自分が分かった風な気持ちになっていることに、気付かされた経験があり、そこからは、一瞬でも分からないことがあれば聞いてみる。とりあえず、自分の認識を言ってみるをするようにした。
当時の自分は、「知っているけど、よく知らない」を「分からないこと」という認識が出来ていなかった。悪気なく、「あー知ってる」と思ってやり過ごしていました。その「ん?」の感情に無頓着だったせいで、たくさんの学びを失ってきたと、その時に気付かされ、それからは分からないを認識するようになりました。
それからは、「ん?」ってなったら、「それってこういうことですか」「僕の認識ではこういうものだと思っていますが、認識合ってますか?」とか本当に分からない時は、「すいません、○○ってなんですか?」と聞くようにしている。(外部の人と話す時は、また違うのかな?分からないけど)
ちょっとした分からないをそのままにして、仕事を進めると、思わぬ巻き戻しが発生したり、本質を掴めず結局良い設計が出来なかったりと、その場の認識合わせの時間以上に時間を消耗することのが多いので、ガンガン聞いてなんぼだと感じている。分からないをそこで解消すると、次はそれが分かるようになるので、話がスムーズに進むようになる。つまり、さっさと聞いた方がその後の時間の効率化にもなる。
あと、単純に「ん?」は学びの瞬間なので、積極的に注目するべき感情と認識した方がお得。 最近、業務が分からないに溢れているので、改めて分からないことを認識していこうと思ったので、記事にしてみた。
インフラのボトルネックについて知る
インフラのボトルネックを理解する
コードはもちろん、リリースしてから安定して動かせるように面倒を見るまでが仕事というのが、弊社の開発スタイルなので、そこで最近学んだことについて、文献や自分の実体験からボトルネックに関する考え方をまとめてみた。
CPUボトルネック
CPU使用率に対する基本的な考え
CPU使用率が80%から90%をずっと推移している!と聞くと、自分のPCの感覚だと、「やばそう」という感覚に陥りますが、インフラにおいての使用率はそうとも限りません。
- CPU使用率高い: うまくリソースを使い切っている
- CPU使用率低い: オーバースペック
ただ、高いCPU使用率にも許容出来る度合いがあったりもするので、そこらへんの判断軸などを踏まえて、まとめてみる。
現実世界の例
CPU使用率が高い状態というのは、実世界に置き換えると、店員がみな忙しく働いているという状態です。利用者からすればオーダーさえ滞りなく通れば文句はなく、経営者もちょうどよい人件費でお店を回せているので、無駄がないと言えます。
システムの例
CPUコアが4つ(店員が4人みたいな)あったとします。それらが全てフル稼働状態だったとします。OSから見た時にCPUの使用率は100%と出ますが、これはネガティブな話ではなく、その逆で、費用対効果が高い状態であり、良い状態と言えます。なぜなら、この状態は他のレイヤーのスループットが非常に高いからです。もし、CPUがボトルネックであったとしても、利用者視点で満足出来る状態であれば問題にはなりません。
なので、CPU使用率が高すぎる!だから良くない!とはすぐに言えず、ユーザーへのレスポンスタイムやスループットに影響がないか?を確認して判断する必要があります。 もし、CPUがボトルネックだったとしても、なぜそうなっているのか?の根本原因を調べることが大事です。
100%は正義ではない
しかし、100%だから効率的だから良い!とも言えません。サービスは成長をします(調子良ければ)。その時に拡張性が担保されている必要はあります。なぜなら、ある日、突然のアクセス増があった時に死んでしまうからです。AWSにはASGという便利な機能があるため、閾値をうまく設定してやれば、突然死ぬことはありませんが、オートスケールは即時制のあるものではありません。(ホットスタンバイとかもありますが)スケールアウトにかかる時間などを加味した上で、上手にリソースを使えるとお金も心にも優しいインフラになると思います。
では、CPU使用率でもよくない高騰した状態ってなんだろう?というところをまとめていく。
待ち行列ボトルネック
ある店舗で、店員が全員忙しく働いているとします。しかし、それでも利用者があまりにも多すぎて、オーダーが通るまで何分も待ち続けるような状態の店があったとします。これはどうでしょう?店員というリソースは完全に使い切っていますが、利用者が明らかにストレスを感じる状況は健全な状態とは言えません。
CPU使用率でも同じことが言えます。処理の方式には待ち行列というものがあります。これはレジの順番待ちのようなものをイメージするとわかりやすいです。CPUの性能に対して、処理待ちのプロセスの質にもよりますが、数が多すぎるという状況になっとします。待ち行列は時間をかければいつか終わりますが、CPUのスループットよりもユーザーからのリクエスト数の方が多いと終わらなくなります。
実店舗などでは、「業務連絡します。3番レジお願いします」などをして、レジを新しくオープンするなどが似たような話です。
システムでは、CPUのコア数を増やして、スループットを高くする。または、プロセスの1処理あたりの時間を短くするなども考えられます。他にはサーバー台数を増やして、並列処理をするようにしたりもできます。
CPUのコア数を増やしたり、サーバー台数を増やしたりするのを、「スケールアウト」と呼んでいます。よく出てくるので覚えておくと話が分かるようになります。
レスポンスボトルネック
スループット問題を解決しても、レスポンス問題が解決するとは限りません。 例えば、ある店舗でのオーダーが、レジ以外にも、商品を作ったり、実際に届けるまでの工程がそもそも時間がかかっていると、店員がどれだけ居ても仕事が回りません。そこで、処理能力そのものをアップさせるという対応を取ることもあります。それが「スケールアップ」と呼ばれているもので、実際には難しいかもしれませんが、店員の処理速度が2倍になれば、処理時間は半分になるので、レスポンスまでの時間が半分になるかもしれません。
処理能力を上げる
CPUにおいては、これをクロック数が先程の店員の処理速度に相当します。CPUのクロック数の単位は「ヘルツ」であり、これは1秒あたりの処理命令数を示しています。 このクロック数を上げることで、一定の効果は得られますが、これには限界があります。どういうことかというと、例えば、店員の一人あたりの単価をアップするよりも(スケールアップする間のダウンタイムは?とかがあったり)、レジの台数を単純に増やすことの方が容易に出来るからです。(拡張性があれば増やすことは簡単なはず) 最近では、スケールアップもオンプレではなく、便利なクラウドがあるので、昔よりは容易なことですが、スケールアップをしたとしても、処理能力を何十倍にも上げるということは難しいでしょう。なによりも、最近のCPUはクロック数にはすごい差があるわけではないので、あまり効果は期待できないケースが多いかもしれません。
並列で処理をする
処理能力はそのままで、処理そのものを分割し、複数のCPUコアに同時処理させる。店員一人が全ての仕事をやるのではなく、それぞれの担当分野を分けるなどです。これで、同時に一人の利用者に対して、複数の店員がいろいろな処理を同時に進めることで、レスポンス時間を短縮するというアプローチです。
この並列で処理するというのは、「並列」、「マルチプロセス」、「マルチスレッド」を使って、一つの処理に対して、CPUコアを複数使うことで、レスポンスタイムの短縮が期待できます。これは、インフラの構成でどうこうというよりも、実際に動いているアプリケーションの改善なので、どういった処理があるのか?などは具体的に掘り下げて、並列化出来るか?をよく検討する必要があります。
CPUの使用率がうまく上がらない
大体のアプリケーションは、CPU使用率が100%に近い状態になることは少なく、ほとんどはCPUから離れたディスクIO、ネットワークIOなどで詰まるケースが多いです。
なぜ、CPU使用率が上がらないかと言うと、例えば、ディスクIOが多い処理があったとします。その場合、システムコールでカーネルに命令が行きます。当然その間は、CPUは待ち状態となり、CPUが休んでいる状態なり、CPU使用率が上がりません。ケースにもよりますが、I/O待ちのキューが多くなり、待機するプロセス数が増加したりします。この状態はCPUはぼとるねっくではありません。これはI/O周りのボトルネックとなっている状態です。もし、ディスクのレスポンスに問題がなかったとしても、CPUやメモリ、I/Oなどのリソースがうまく活用されていないと、全体の処理が遅くなることがあります。
こういった問題の解決には、2つのアプローチがあります。 一つは、同期I/O命令をスレッドごとに命令して、並列実行することで、CPU使用率もI/Oの負荷も上げる。もう一つは、I/Oを非同期化することで、I/O処理の完了待たずに次に進めていく。そうすることで、CPU処理とI/O処理を並行して進めることで、リソースをうまく使う。
メモリボトルネック
僕がやっていた仕事では、まだ遭遇したことがありませんが、いくつかよくあるボトルネックをまとめてみました。
ここでいうメモリとは、「補助記憶装置」ではなく、「主記憶装置」と呼ばれるRAMのことを指しています。 メモリは、CPUの計算結果などを記憶するものです。アクセス速度は補助記憶装置としてよく出てくるHDDやSSDなどに比べると段違いに速いです。全てを主記憶装置と呼ばれるメモリにしないのは、メモリは電気が通っていないと書き込まれていたデータが消えてしまう揮発性のメモリだからです。
スワップによるアクセス速度の低下
メモリに関連して起きる問題は、基本的にメモリ自身に問題が発生するというよりは、周りにしわ寄せが来る印象です。よくあるのがスワップの大量発生によるアクセス速度の低下による全体の処理性能が落ち込む減少です。
スワップとは、メモリの容量が足りなくなった時に、メモリの内容をハードディスクなどの補助記憶装置に移す機能のことです。これによってどういうことが起きるかというと、先にも書いた通り、HDDなどのアクセス速度はメモリと比べると、かなり遅いです。最近ではSSDなどの高速アクセス可能な補助記憶装置も出てきていますが、それでもメモリの方が速いです。 こうなると、発生する問題としては、アクセス時間が長くなり、結果的に処理完了時間が長くなります。
サーバーの状態を見ると、CPU使用率がかなり余裕で、メモリは100%近く使っているといった感じになります。なぜなら、CPUの待ち時間が長くなるので、使用効率が悪くなるからです。こうなると本来の力が発揮できなくなっていると言えます。
メモリがスワップされているかは、freeコマンドを使うと調査ができます。
もし、スワップが大量発生している場合は、メモリリークしているものがないか?とか、メモリに大きなサイズのものを載せすぎでは?などが考えられます。
Linux のメモリー管理(メモリ−が足りない?,メモリーリークの検出/防止)(Kodama's tips page)
その他
書いてて疲れたので、次に行きます。
ディスクI/Oボトルネック
ディスクI/Oは、今までのメモリやCPUに比べると非常に遅いものになります。最近では、SSDなどの高速なディスクもありますが、それでも遅いです。 ディスク周りがボトルネックになるケースは、CPUの使い方を工夫するだけでは、効果があまり上がりません。I/Oの効率が上がるようにするか、I/Oを減らす工夫が必要です。
DBサーバー
ディスクI/Oが発生する先として、以下のような種類のものが、よく出てきます。
- ローカルストレージ: サーバー内部のディスク
- SAN(Storage Area Network)
- NAS(Network Attached Storage)
そして、これらを活用することがあるDBサーバーのボトルネックを見ていきます。
まずは、それぞれを使う場合の通信経路の違いについて
DBサーバー <-> SANスイッチ <-> SANストレージ DBサーバー <-> ネットワークスイッチ <-> NASストレージ DBサーバー <-> 内部ディスク
アプリケーションから見ると、その先で何が使われているかなどを気にする必要はありません。OSカーネル側でリクエストを必要なプロトコルに変換し、ディスクやストレージにリクエストを送ります。確かに動作させる側としては、特に違いを意識する必要はありませんが、インフラを見る側の人間だとこの違いを知る必要があります。
まず、性能の違いについて、これはある程度、前提条件を設定させてもらいます。例えば、ローカルディスクが3~4のディスクでRAID構成を組んでいて、キャッシュにはサーバー上のOSのメモリが利用されているとします。 それに対して、ストレージは何十という単位でディスクを配置してあり、更にキャッシュ専用のメモリ領域が容易されています。ディスクは数によってスループットが向上しますので、外部ストレージのがスループットの面では高い能力を発揮すると言えます。(多くの場合は)
スループットは、同じ領域え利用しているユーザーが多ければ多いほどに低下します。しかし、逆にローカルディスク側はディスクを専有できている点では良いのですが、他のアプリケーション領域と共有している可能性があります。OSのストレージに対しる設定に依存するので、気をつけるべきです。
レスポンスという点では、基本的には近い方が速いので、単体のレスポンスはローカルディスクが最速になります。なので、この差を埋めるために、外部ストレージでは、メモリ領域の活用やデータのキャッシュを効率よく使うなどをして、レスポンス改善に努めています。
今回はスループットやレスポンスという点だけで、ストレージを見ましたけど、実際は対象外性なども入れて考えると、もっと考えるべきポイントが増えてきます。また、さらっと書きましたけど、導入コストの問題を考えたりすると、また面倒だったり・・・(最近はクラウドが便利なので考えること減りましたがw)
HDDやSSDの違いについて知ると、また面白いので良い記事を紹介しておきます。
ネットワークI/Oボトルネック
ネットワークI/Oのボトルネックはレスポンスタイムのオーバーヘッドに大きく影響します。レスポンス時間の改善をすることは難しいため、そもそも、I/Oが発生する回数を減らすアプローチが有効です。
通信プロセスボトルネック
ネットワーク回線において、帯域というのが重視されることが多いです。帯域が大きいと高速であるわけでないです。 まず、前提として、1つのプロセスで処理をしている場合、高スループットを実現することは難しいです。それは、「データ転送」「通信結果の確認」と言ったやり取りが発生するからです。もし、帯域を使い切ったような通信を行いたい場合、処理を多重化し、並列化する必要があります。そうすることで、通信量が増え、より上限に近いスループットが実現できます。また、そのやり取りに使っているデータを圧縮して、転送量をへらすというのも良いアプローチにはなりますが、圧縮や解凍はCPUオーバーヘッドとトレードオフになります。
ネットワーク経由のボトルネック
ネットワークで起きているボトルネックは目には見えにくいです。実際に処理をしているAPサーバーやDBサーバーなどは、レスポンスタイムが長くなった原因が読み取れません。逆に言うと、特に問題が見えない場合は、ネットワーク系で問題が起きているとも考えられます。
例えば、デフォルトゲートウェイがさばけるトラフィックの限界を迎えていた場合、ここがボトルネックとなり、全体の処理効率がある一定のラインで止まってしまうでしょう。
アプリケーションボトルネック
これまでのインフラの「スケールアップ」「スケールアウト」を使うことで、増強や分散が可能とは書きましたが、そもそもアプリケーション側がそれに対応していないとボトルネックになることがあります。
データ更新ボトルネック
特定のデータに依存した処理に対するボトルネック。 どういうことかというと、あるAというリソースにデータ更新をしにいってるプロセスがあるとします。同じAに対するデータ更新したいプロセスが複数あったとしても、同時に更新することは出来ないので、処理待ちが発生します。そのため、どれだけ処理スピードが上がったとしても、データ更新部分でボトルネックとなります。
解決策はいくつかあって、一つは値をキャッシュ化して、DBサーバーへ問い合わせをせずに内部である程度完結させることで、処理効率を上げる。しかし、これだと根本的な解決にはなりません。 一つは毎度DBに問い合わせることをやめて、RDB以外の場所にRDBに適用するべき内容をためておき、それらを精査して、一定タイミングで適用をしていく(結果整合性)。これではデータのリアルタイム性は失われる可能性があります。これが許容出来ない場合は、データベースの機能などを使って行を分割して同時処理を可能にすることや、そもそも表そのものを分けたりなどをしたりすることも考えられます。サービスの質的に何が担保されている必要があるかによってアプローチは変わってきますので、ここはいろいろある。(雑なまとめ)
他にもいくつかありますが、とりあえず、こんなところにする。
実務から大体一ヶ月経ったので振り返り
振り返りをしてみた
やりっぱなしも良くないなーと思ったので、一ヶ月ごとくらいに振り返りをしていこうと思う。 期間は大体、仕事が始まった4月中旬から、今日までです。
よかったこと
- 質問を遠慮せず、他のクルーにガンガンできた。(弊社では社員のことをクルーと呼んでいます)
- 分からないことを分からないと言うようにした
- 業務中に眠いことがなくなった
- 生活リズムを崩さなかった
- 睡眠に本気出した
- 自分のやっている作業をissueとPRから分かるようにした
- 黙々とやらずに、ガンガン書くようにした
- 口頭で行った意思決定も書く
- AWSのコンソールに慣れた
- 様々な言語が出てくるのに対して、何も感じない(毛嫌いしない)
- アドテク用語のキャッチアップ頑張った
- 何でこうなってるんですか?を解消した
- 違和感をそのままにしない
- 違うチームの人へもコミュニケーションを取りに行った
- 周りを巻き込む意識(いい意味で)
- 予定が無ければ、毎朝毎晩勉強した
- 早寝早起き
- OSSも地味に継続して活動した
気をつけたいこと
- なんでこうしたの?が答えられないことがある
- 知識不足もあるけど、意識次第で回避できそう
- 作業の影響範囲に対しての認識が曖昧
- これをやることによって誰が困るんだろう?を考える
- 自信が無いせいか、違う意見が出てくると不安になる
- なぜやるのか?をもっと掘り下げて、自信を持つ
- 本番へのリリース作業に心労しすぎ
- ほんと、慣れたい。。。
- 複数タスクをこなしたくなる。
- 一つ一つやっていこう
- 焦りから、意思決定を急ぎすぎ
- 結果は地道に出していこう
- 問題が起きた時の、問題の切り分け
- 感情先行しがちなので、客観視しよう
- リスクに対しての意識を高める
- どういうリスクがあるか?
- どこまでのリスクは許容できるのか?
- 実際に問題が起きた時に戻せるか?
- 営業さんが言っていることが、理解しきれていない
- 営業さんにも、話を聞いていこう
- 話がまとまっていない
- 結論から言う
- 簡潔に伝える
- 要点を押さえる
6月もガンガンやってくぞー。
登壇経験の棚卸ししてみた
自分的に一段落着いたと感じたこともあり、一度、経験を棚卸ししてみた 今までの登壇の種類とかをまとめてみると以下のような感じ。
- 座学
- ワークショップ
- ハンズオン
- カンファレンストーク
- ライブコーディング
- LT(これは登壇?なのか?)
それぞれについて、詳しく経験をまとめたいところですが、非常に長くなりそうなのでry
登壇は学びの宝庫
登壇は最大のアウトプットにして、最大のインプット。つまり、学びの宝庫であると僕は思っています。もちろん、良いことばかりではありません。事前に資料とか構成を決めるのは大変ですし、発表に対するアンケート結果とかを見て、胸を痛めることもあります。しかし、そこで得られる経験は挑戦しなければ得られないものなので、後で自分のためになることばかりです。
ちなみに、アンケート結果などで心が痛まないのか?という人向けに先に解答をしておくと、私も人間なので当然痛いです。私なりにやっているアンケート結果の使い方は、すごく極端な評価をしている人の意見に注目するのではなく。(極端に高いとか低い点数のこと)中間あたりの評価をつけている人たちをどうすれば満足と思わせることが出来たのか?ということに注目するようにして、次回の発表に活かすようにしています。極端に悪いところばかりに目が行きがちですが、大半はどっちでもない人達なので、その人達に向けて何が出来るか考える方が建設的です。
他人に説明することで、知識が整理される
俺は理解した!と感じつつも、いざ発表するとなると、アレ?これってどういう風に言えばよかったんだっけ?みたいなことが起きがち。なので、理解したという自信をつけたいトピックをテーマにするのは結構ありだと感じています。
分からないが見える化
人に説明するとなると、大体の人が自分で理解する時以上に、丁寧に調べると思います。そうすると、アレ?これってなんだろうが出て来ることがあります。そうした過程で、知識が穴ぼこになっていたところが綺麗に埋められ、発表する前よりも深く理解が出来た状態になったりします。
発表をすると、フィードバックが得られる
登壇後などの懇親会などで、直接やSNS上で、自分の話した内容に対しての意見やフィードバックが得られることが結構あります。これが一番の学びの瞬間。また、そこから新たな議論が生まれたり、改善点が見えたり、新しく話すべきトークテーマが出てきたりします。発表をした時こそ、色々な人と話すようにすると学びが加速するので、積極的に話すと効果が最大化すると感じている。
それぞれの発表形式ある気をつけるべき点
今後、発表したいなーと感じている人向けにちょっとアドバイスっぽいものを書いてみた。
座学
普通にやると暇になりがちなので、参加者へ質問を投げかけたり、質問をたくさん受けるようにした方が良さそう。
ハンズオン
どんなOSでも動くようにしておくか、参加者へ前提条件を提示しておく。
カンファレンストーク
みんなに満遍なくウケる話を意識しすぎると、つまらなくなりがちなので、俺の思う面白い話!みたいなノリくらいで良かったり。
ライブコーディング
色んな人に理解してもらうために、丁寧にやりすぎる時間が無限に足りないので、ある程度見切りをつけてガンガン進めて、本来やりたかったところまで達成するようにした方がいい。また、ある程度どうやって進めるのかは台本を用意して、がっつり準備するくらいで良いw
LT
勢い命。
まとめ
4月から社会人になったので、これからは質も上げれるように頑張っていきたい。
登壇で今後大事にすること
登壇で伝えたいことは事前に言語化して、聴衆にそれを持ち帰ってもらうことを意識する。
未だによくある失敗なのですが、当日想定していたよりも、寄り道が増えてしまったりして(寄り道というのは前提知識のインプットとかで色々派生してとか) 、本来伝えたかったことがうまくまとまらず終わってしまうことがあるので、気をつけていきたい。
【swaggo】GoのGoDocからSwaggerを書き出そう(基本編)
swaggo

今回紹介するswaggoはyvasiyarov/swaggerにインスパイアを受けて、作成したOSSになります。現在、yvasiyarov/swaggerは開発が止まっているので、いくつかの問題が放置されたままになっています。(これはOSSなので仕方ないです) swaggoは元の構文をそのまま流用して、機能追加をしているものになります。
- Swagger 2.0の対応
- 複雑な構造体の解析
- カスタムヘッダー
- example value
- セキュリティ
私がざっと見た限り、上の内容はswaggoで無ければ使えないっぽいです。
Swagger便利だけど、書くのがそもそもだるい
最近になって、よくSwaggerというワードを目にするようになりました。これはとても画期的で、APIに実際にリクエストを投げれるドキュメントが出来上がります。 しかし、このドキュメントのコードを書くのが結構面倒!
もし、既に実装されているコードからSwaggerを生み出すことが出来るものがあったら、最高ですよね?ということで、今回はswaggoを使ったドキュメント生成を紹介します。
実装方法
だらだら書いても仕方ないので、さくっとコード例を書きます。 今回の記事に使ったコードはこちらにあります。 また、今回、紹介する内容は、公式ドキュメントに詳しく記載があります。
General API Info
Swaggerの基本情報をmain.go(オプションで変えることも出来ます)に書きます。 設定出来る項目
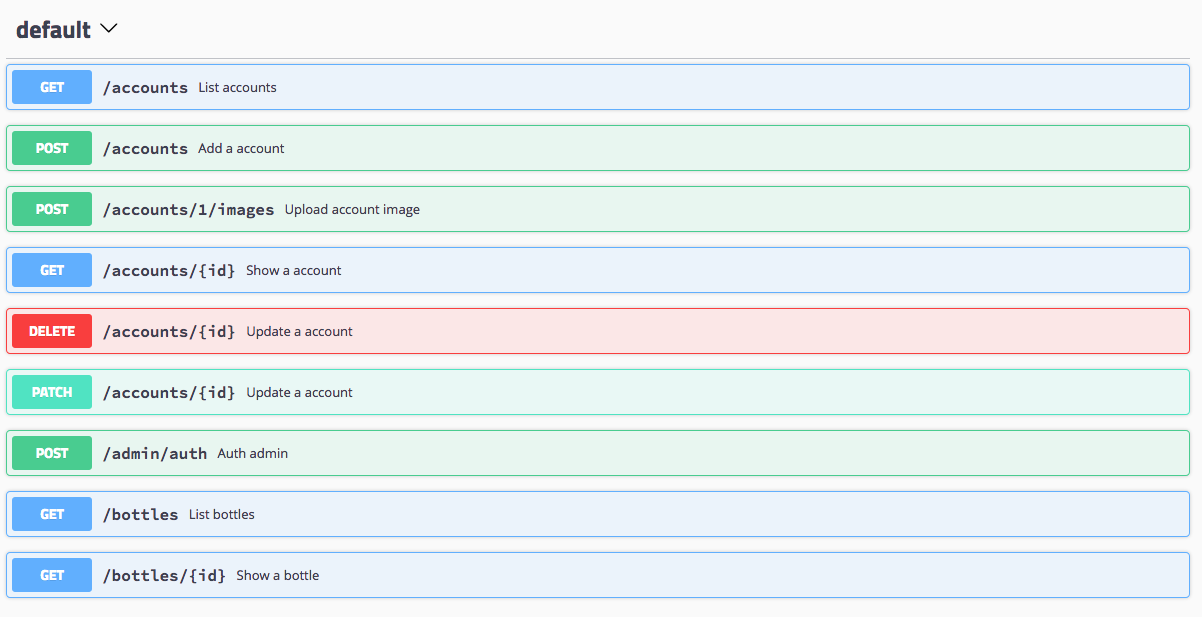
package main import ( "github.com/gin-gonic/gin" "github.com/swaggo/gin-swagger" "github.com/swaggo/gin-swagger/swaggerFiles" "github.com/swaggo/swag/example/celler/controller" _ "github.com/swaggo/swag/example/celler/docs" ) // @title Swagger Example API // @version 1.0 // @description This is a sample server celler server. // @termsOfService http://swagger.io/terms/ // @contact.name API Support // @contact.url http://www.swagger.io/support // @contact.email support@swagger.io // @license.name Apache 2.0 // @license.url http://www.apache.org/licenses/LICENSE-2.0.html // @host localhost:8080 // @BasePath /api/v1 // @securityDefinitions.basic BasicAuth // @securityDefinitions.apikey ApiKeyAuth // @in header // @name Authorization // @securitydefinitions.oauth2.application OAuth2Application // @tokenUrl https://example.com/oauth/token // @scope.write Grants write access // @scope.admin Grants read and write access to administrative information // @securitydefinitions.oauth2.implicit OAuth2Implicit // @authorizationurl https://example.com/oauth/authorize // @scope.write Grants write access // @scope.admin Grants read and write access to administrative information // @securitydefinitions.oauth2.password OAuth2Password // @tokenUrl https://example.com/oauth/token // @scope.read Grants read access // @scope.write Grants write access // @scope.admin Grants read and write access to administrative information // @securitydefinitions.oauth2.accessCode OAuth2AccessCode // @tokenUrl https://example.com/oauth/token // @authorizationurl https://example.com/oauth/authorize // @scope.admin Grants read and write access to administrative information func main() { r := gin.Default() c := controller.NewController() v1 := r.Group("/api/v1") { accounts := v1.Group("/accounts") { accounts.GET(":id", c.ShowAccount) accounts.GET("", c.ListAccounts) accounts.POST("", c.AddAccount) accounts.DELETE(":id", c.DeleteAccount) accounts.PATCH(":id", c.UpdateAccount) accounts.POST(":id/images", c.UploadAccountImage) } /... } r.GET("/swagger/*any", ginSwagger.WrapHandler(swaggerFiles.Handler)) r.Run(":8080") }
API Operation
エンドポイントに関する情報書きます。 設定出来る項目 よく使う項目をピックアップして説明致します。
package controller //... // ShowAccount godoc // @Summary Show a account // @Description get string by ID // @Accept json // @Produce json // @Param id path int true "Account ID" // @Success 200 {object} model.Account // @Failure 400 {object} controller.HTTPError // @Failure 404 {object} controller.HTTPError // @Failure 500 {object} controller.HTTPError // @Router /accounts/{id} [get] func (c *Controller) ShowAccount(ctx *gin.Context) { id := ctx.Param("id") aid, err := strconv.Atoi(id) if err != nil { NewError(ctx, http.StatusBadRequest, err) return } account, err := model.AccountOne(aid) if err != nil { NewError(ctx, http.StatusNotFound, err) return } ctx.JSON(http.StatusOK, account) }
エンドポイントの説明
// @Summary Show a account` // @Description get string by ID`
MimeType
// @Accept json // @Produce json
APIが許可しているMimeTypeを設定できます。 設定出来るMimeType
Param
// @Param パラメーター名 種類 型 必須要素か? コメント
// @Param id path int true "Account ID" // @Param q query string false "name search by q" // @Param account body model.AddAccount true "Add account" // @Param Authorization header string true "Authentication header"
- path: パスパラメーター
- query: クエリパラメータ
- body: そのまんまです
- header: カスタムリクエストヘッダー
パラメーターの型として、string, int, fileなどが利用が出来ます。
Result
// @Success ステータスコード パラメーターの型 データの型 コメント
// @Success 200 {object} model.Account // @Failure 400 {object} controller.HTTPError // @Failure 404 {object} controller.HTTPError // @Failure 500 {object} controller.HTTPError
成功のパターンと失敗のパターンを必要分だけ用意します。
構造体の指定の仕方
// @Success 200 {object} model.Account
上記のように書くと、package名.構造体名のような感じで探しに行って、ヒモ付を行なってくれます。
package model // ... type Account struct { ID int `json:"id" example:"1"` Name string `json:"name" example:"account name"` }
exampleに設定された値は、Swaggerで出した時の具体例として設定されます。
jsonに設定された値は、JSONのキー名を決定します。
つまり、上記の例の場合、{"id": 1, "name": "account name"}というJSONが出来上がります。
Security
// @Security ApiKeyAuth
General API Infoで定義したセキュリティを使うことが出来ます。これの使い方については、別の記事で詳しく取り上げる予定です。
Authentication - Swagger
Router
// @Router /accounts/{id} [get]
エンドポイントのURIとメソッドを指定します。このURIはGeneral API infoでのBasePathからの相対パスを設定する必要があります。
// @BasePath /api/v1
今回の場合だと、最終的に出来上がるエンドポイントは、/api/v1/accounts/{id}となります。
Swaggerコード生成
$ go get -u github.com/swaggo/swag/cmd/swag $ swag init
上記をmain.goのあるパスで実行すると、docsフォルダが出来上がります。そこに、swaggerドキュメントに関するコードが生成されます。
. ├── README.md ├── controller ├── docs <-- これが自動生成される │ ├── docs.go │ └── swagger │ ├── swagger.json │ └── swagger.yaml ├── main.go └── model
i -h NAME: swag init - Create docs.go USAGE: swag init [command options] [arguments...] OPTIONS: --generalInfo value, -g value Go file path in which 'swagger general API Info' is written (default: "main.go") --dir value, -d value Directory you want to parse (default: "./") --swagger value, -s value Output the swagger conf for json and yaml (default: "./docs/swagger")
ちなみに、このinitコマンドには、上記のようなオプションがあるので、自分の環境に合わせて変更が可能です。
//... "/accounts/{id}": { "get": { "description": "get string by ID", "consumes": [ "application/json" ], "produces": [ "application/json" ], "summary": "Show a account", "operationId": "get-string-by-int", "parameters": [ { "type": "integer", "description": "Account ID", "name": "id", "in": "path", "required": true } ], "responses": { "200": { "schema": { "type": "object", "$ref": "#/definitions/model.Account" } }, "400": { "schema": { "type": "object", "$ref": "#/definitions/controller.HTTPError" } }, "404": { "schema": { "type": "object", "$ref": "#/definitions/controller.HTTPError" } }, "500": { "schema": { "type": "object", "$ref": "#/definitions/controller.HTTPError" } } } }, //...
実際にSwaggerからリクエストを投げてみよう
swaggerのコードを読み込んで、使うのも良いですが、今回はswaggoが用意している便利な関数を使って、UIを呼び出したいと思います。ちなみに、そのコードは既に例に含まれています。
r.GET("/swagger/*any", ginSwagger.WrapHandler(swaggerFiles.Handler))
http://localhost:8080/swagger/index.htmlには既にSwaggerUIが展開されており、リクエストが出来る状態になっています。 このハンドラは、gin Echo net/httpをサポートしています。対応していないものを使っている場合は、自分でSwaggerUIを用意する必要があります。(PR投げれば種類を増やせます!)
まとめ
現状、簡単なAPIなら十分ドキュメント生成に活用出来ます。是非使ってみてください。 あと、自分が関わっているOSSということもあり、意見募集中です!w
学生は勉強と実践どちらが大事なんだろうか: HAL Advent Calendar 2017
HAL Advent Calendar 2017
今年も頑張るぞい 。 私はいまHAL大阪という学校に通っている「ぺい」です。最近はGo言語がマイブームです。いま力を入れて勉強しているのはインタプリタと英語です。
学生は勉強と実践どちらが大事なんだろうか
結論: 陳腐化しない内容を勉強する。実践はいずれ誰でもすること。
いまの自分のままで大丈夫か?という”焦り”
就職を来年に控えて、エンジニアとして生きていくわけなんですが、「学校の授業は全く役に立たないので、さっさと働いて実力つけたい!」と結構前から思っています。その背景にあるのは、”焦り”です。そういう感情が生まれたのは、昨年のインターンで同期の優秀なエンジニア達との交流からで、このままじゃ自分は通用しない!大変だ!とどこかで焦っているからだと思います。恐らくこの記事を読んでいる人の中にも、私と同じように解消されない焦りを抱えている人や、どこかで不安を感じている人はいるでしょう。今回はそういった人向けに、今年一年間で私なりに出た結論を紹介致します。何か参考になれば幸いです。
実践で学べないことはある
「勉強するよりも、実践を積み重ねた方が実力伸びるんじゃね?」と考えた人はいると思いますが、実践では学べないこともあります。それは会社に入社する場合でも、起業をする場合であってもです。 それは、業務に直接必要がない知識です。では、自分のケースで考えてみましょう。
入社予定の会社は、アドテクやメディアをメイン事業として展開しており、社内だけで幅広い分野に携わることが出来る。また、定期的に技術審査会が行われるので、自分の実力などを客観的に評価されるタイミングを定期的に得ることが出来る。 現状は海外展開が目立って行われていないので、エンジニアは英語を業務で使うことはない。
仕事の中で学べそうなこと
- パフォーマンスチューニング
- BtoC BtoBのシステム開発
- インフラ、サーバーサイド、フロントなど様々な開発
- レビュアー、レビューイ
- その他色々
恐らく仕事で学ぶ可能生がないこと
ここで分かることは、開発経験などは仕事で結構出来そうです。(もし、東京在住なら内定者バイトいてますが・・・w) 逆に、英語や低レイヤな内容は、業務でやらなさそうなので、何年間やったとしても体得することは出来なさそうです。 ここで言いたいことは、実践だけでは得られない知識は存在するということです。
役に立たない = すぐ使えないもの ≠ ずっと役に立たない
いま自分は、インタプリタと英語の勉強をしています。そんな業務で使わないようなものなのに、それって意味ある?と思う方はいると思います。これは確かにお金には直結しないかもしれません。しかし、いま学んでいる内容は、今後長く使える知識だということが重要です。つまり、見えている将来では役に立たないかもしれませんが、もっと先の将来では役に立つかもしれません。 例えば、いま私が読んでいる本はWriting An Interpreter In Goで、全て英語で書かれている洋書です。これを読むモチベーションは、いままで書いてきたプログラムは動いているのかを少しでも理解したい気持ちとASTを使ったコード生成に興味が湧いたからです。また、洋書は読むのが結構辛いのですが、英語の勉強を丁度していたので、どうせならまとめて勉強出来るから、頑張ってみようと始めました。ちなみに英語は週に一回ペースで、英会話に通っています。 インタプリタにしても、英語にしても、共通しているのは、一度学べば陳腐化することはあまり無い。しかし、習得にかなりの時間を要することです。こういう特徴を持ったものを社会人になってからやるのは結構辛いです。だからこそ、いま実践よりも優先して学ぶことにしました。
時間がある内に出来ることに注目
内定先でバイトしたり、もっと実践的な場に身を置きたい!などの気持ちは分かります。私みたいに住んでいる場所や学校のカリキュラム的に無理という人は居ると思いますが、実践はいずれみんなすることです。いまだからこそ出来ることはあるので、探してみることをおすすめします。